Redis:基本架构、数据结构和高性能IO模型
本站字数:108k 本文字数:4.4k 预计阅读时长:15min 访问次数:次Redis 作为一个越来越受欢迎的中间件,Redis 有关的一切都变得很重要。本文从 Redis 的基本架构、支持的数据结构和 Redis 的高性能 I/O 模型展开。
基本架构
说起Redis一般都会联系到 Redis 的常见应用场景,缓存、秒杀、分布式锁等重要场景。下面将从系统层面建立一个 SimpleKV ,构建过程中主要包括:数据结构和操作接口两个重要的组成部分,同时还有若干问题,例如数据的存储位置,数据的访问方式、定位键值对的方式,实现重启后快速恢复服务等等问题。
应该使用什么样的数据结构?
对于一个key/value数据库模型,key是String,value是基本类型,例如,String、整数等等。作为一个简单的KV数据库,只需要支持简单的数据结构即可。对于实际生产环境中,value还可以是复杂的数据类型。
不同键值数据库支持的key类型一般差异不大,而value类型则有较大差别。我们在对键值数据库进行选型时,一个重要的考虑因素是它支持的value类型。例如,Memcached支持的value类型仅为String类型,而Redis支持的value类型包括了String、哈希表、列表、集合等。Redis能够在实际业务场景中得到广泛的应用,就是得益于支持多样化类型的value。
SimpleKV应该拥有怎么样的数据操作?
SimpleKV 主要支持3中基本类型:PUT\GET\DELETE
- PUT:新写入一个值或者更新一个KV对
- GET:根据一个key读取相应的value值
- DELETE:根据一个KEY删除一个KV数据对
在实际的业务场景中,我们经常会碰到这种情况:查询一个用户在一段时间内的访问记录。这种操作在键数据库中属于SCAN操作,即根据一段key的范围返回相应的value值。因此,PUT/GET/DELETE/SCAN是一个键值数据库的基本操作集合。
键值对应该保存到内存还是应该保存到外存?
如果键值对保存到内存中,可以得到数据的高速访问。但是,会有因为掉电而失去所有数据的风险。
如果键值对保存到外存中,可以获得更大的存储空间,不会受到内存大小的限制,而且可以避免数据关机而丢失。但是会受制于磁盘速度的影响。
因此,如何进行设计选择,我们通常需要考虑键值数据库的主要应用场景。比如,缓存场景下的数据需要能快速访问但允许丢失,那么,用于此场景的键值数据库通常采用内存保存键值数据。Memcached和Redis都是属于内存键值数据库。对于Redis而言,缓存是非常重要的一个应用场景。后面我会重点介绍Redis作为缓存使用的关键机制、优势,以及常见的优化方法。
SimpleKV 应该使用什么样的访问模式?
访问模式通常有两种:一种是通过函数库调用的方式供外部应用使用,比如,下图中的libsimplekv.so,就是以动态链接库的形式链接到我们自己的程序中,提供键值存储功能;另一种是通过网络框架以Socket通信的形式对外提供键值对操作,这种形式可以提供广泛的键值存储服务。在下图中,我们可以看到,网络框架中包括Socket Server和协议解析。
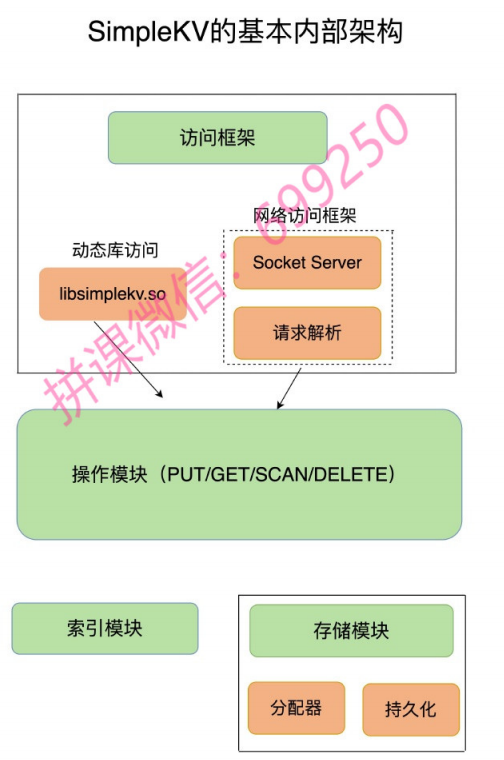
如何定位键值对的位置?
当SimpleKV解析了客户端发来的请求,知道了要进行的键值对操作,此时,SimpleKV需要查找所要操作的键值对是否存在,这依赖于键值数据库的索引模块。索引的作用是让键值数据库根据key找到相应value的存储位置,进而执行操作。
索引的类型有很多,常见的有哈希表、B+树、字典树等。不同的索引结构在性能、空间消耗、并发控制等方面具有不同的特征。如果你看过其他键值数据库,就会发现,不同键值数据库采用的索引并不相同,例如,Memcached和Redis采用哈希表作为key-value索引,而RocksDB则采用跳表作为内存中key-value的索引。
如何实现重启后快速恢复服务?
SimpleKV可以使用内存来达到微秒级别的key查找效率,依赖于内存的保存。但是保证SimpleKV能够在重启后重新提供服务,所以,在SimpleKV存储模块中添加持久化功能也是很有必要的。
一种方式是,对于每一个键值对,SimpleKV都对其进行落盘保存,这虽然让SimpleKV的数据更加可靠,但是,因为每次都要写盘,SimpleKV的性能会受到很大影响。
另一种方式是,SimpleKV只是周期性地把内存中的键值数据保存到文件中,这样可以避免频繁写盘操作的性能影响。但是,一个潜在的代价是SimpleKV的数据仍然有丢失的风险。
SimpleKV 到 Redis 演进
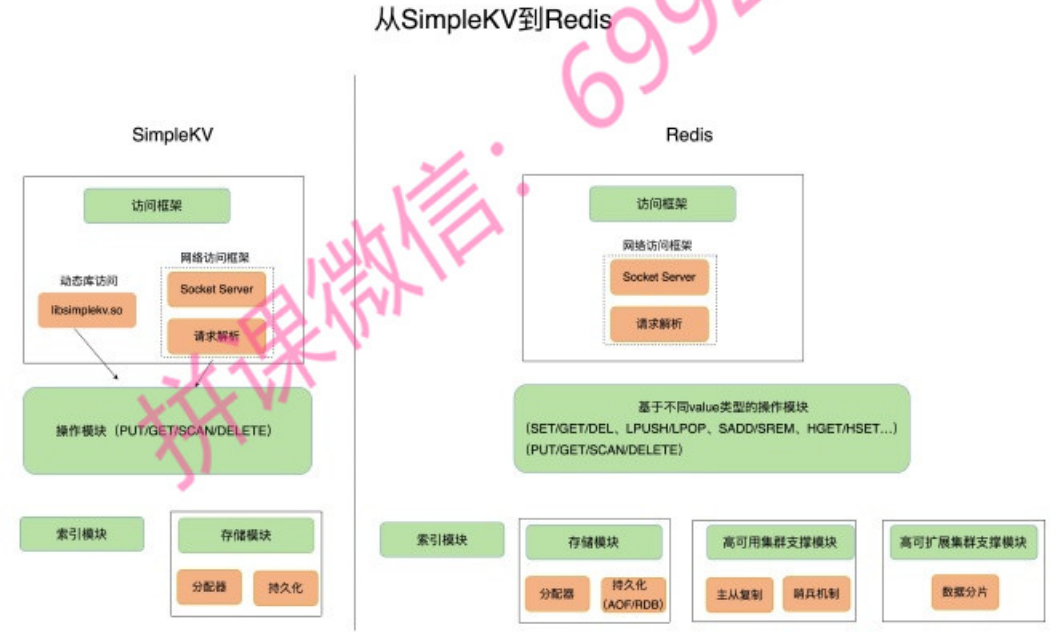
- Redis主要通过网络框架进行访问,而不再是动态库了,这也使得Redis可以作为一个基础性的网络服务进行访问,扩大了Redis的应用范围。
- Redis数据模型中的value类型很丰富,因此也带来了更多的操作接口,例如面向列表的LPUSH/LPOP,面向集合的SADD/SREM等。
- Redis的**持久化模块能支持两种方式:日志((AOF)和快照(RDB)**,这两种持久化方式具有不同的优劣势,影响到Redis的访问性能和可靠性。
- SimpleKV是个简单的单机键值数据库,但是,Redis支持高可靠集群和高可扩展集群,因此,Redis中包含了相应的集群功能支撑模块。
数据结构
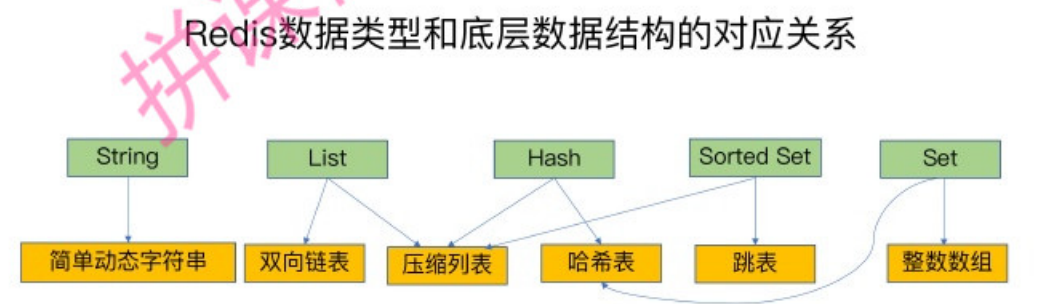
Redis 使用了什么样的方式存储这么多的键值对?
Redis 使用了一个全局的 Hash 表,来存储所有的键值对。
一个哈希表,其实就是一个数组,数组的每个元素称为一个哈希桶。所以,我们常说,一个哈希表是由多个哈希桶组成的,每个哈希桶中保存了键值对数据。
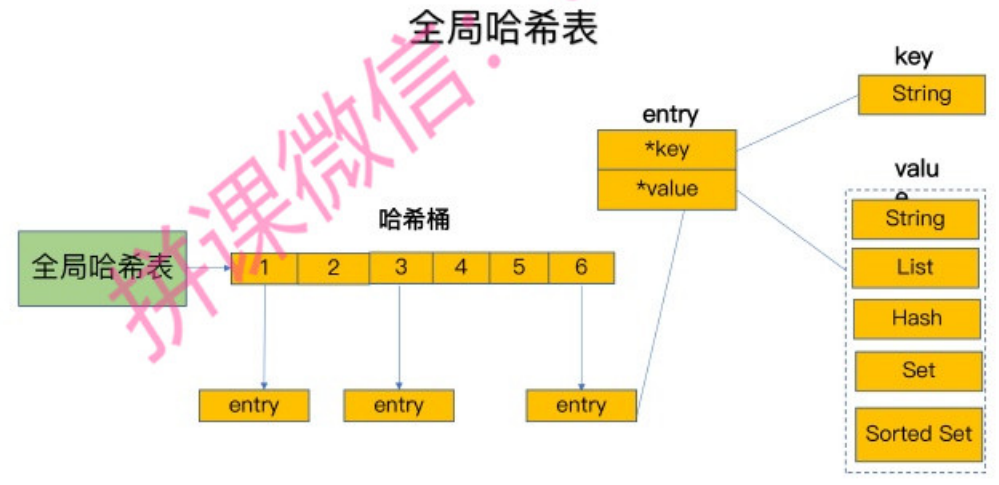
但是,如果你只是了解了哈希表的 O(1) 复杂度和快速查找特性,那么,当你往 Redis 中写入大量数据后,就可能发现操作有时候会突然变慢了。这其实是因为你忽略了一个潜在的风险点,那就是哈希表的冲突问题和 rehash 可能带来的操作阻塞。
为什么 Hash 表操作变慢了?
在往 Hash 表里面插入数据的时候,哈希冲突是完全不可避免地。Hash 冲突的时候,往往有几种常见的解决方案,比如,线性寻址,平方寻址,链地址,或者如 JDK 中 HashMap 的链表 + 红黑树的解决方案。
Redis解决哈希冲突的方式,就是链式哈希。链式哈希也很容易理解,就是指同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接。
查询 key 的时候,在 Hash 链上面通过指针逐一查询。但是,Hash 链变长以后,这个查询效率就会下降。
所以,Redis会对哈希表做 rehash 操作。rehash也就是增加现有的哈希桶数量,让逐渐增多的entry元素能在更多的桶之间分散保存,减少单个桶中的元素数量,从而减少单个桶中的冲突。
如何高效 Rehash ?
就像把大象关进冰箱一样,rehash 也分为三步:
- 给哈希表2分配更大的空间,例如是当前是哈希表大小的2倍为什么 Rehash 一般新的数组是原来的2倍?
- 减少元素的移动量:每个元素对于新的容量,要么移动要么不移动
- 使得元素能够均匀散布到 HashMap ,减少 Hash 碰撞:让元素能够均匀分布到后半部分
- 对哈希表1中每个 Hash 桶中的键值对进行拷贝迁移
- 释放哈希表1的空间
上面的过程其实不难理解,但是第二步涉及整个 Hash 表的数据迁移。因此这个过程也是非常的消耗性能。再加上 Redis 是单线程工作的,在 Rehash 过程中,无法处理其他的请求。这个时候Redis没办法快速访问数据了。
为了避免这个问题,Redis 采用了渐进式 Rehash的解决方案。
简单来说就是在第二步拷贝数据时,Redis仍然正常处理客户端请求,每处理一个请求时,从哈希表1中的第一个索引位置开始,顺带着将这个索引位置上的所有entries拷贝到哈希表2中;等处理下一个请求时,再顺带拷贝哈希表1中的下一个索引位置的entries。如下图所示:

在寻找到值以后,就需要对值进行操作了,对值的操作的时间复杂度和数据结构本身息息相关。
在上面提到的数据结构中,整数数组,哈希表,双向链表其实都是比较常见的数据结构,时间复杂度这里也不再赘述,下面主要讨论两种不太常见的数据结构,一个是压缩列表,另一个是跳表。
压缩列表 和 跳表
压缩列表实际上类似于一个字节数组,数组中的每一个元素都对应保存一个数据。和数组不同的是,压缩列表在表头有三个字段zlbytes、zltail和zllen,分别表示列表长度、列表尾的偏移量和列表中的entry个数;压缩列表在表尾还有一个zlend,表示列表结束。

在压缩列表中,查找头部和尾部的数据时间复杂度为 O(1)。但是对于其他数据,就需要顺序查找了。
接下来是跳表。
有序链表只能逐一查找元素,导致操作起来非常缓慢,于是就出现了跳表。具体来说,跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位,如下图所示:

跳表其实在查找过程中就是在索引上跳来跳去,最后定位到元素,因此这个过程就称之为跳表。跳表的时间复杂度是 O(logN)。
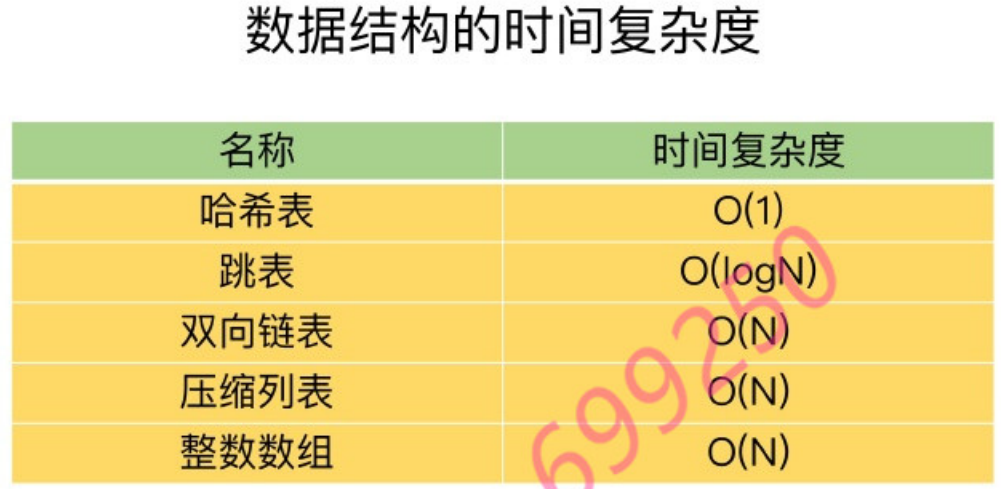
不同操作的复杂度
- 单元素操作是基础;
- 范围操作非常耗时;
- 统计操作通常高效;
- 例外情况只有几个。
第一,单元素操作,是指每一种集合类型对单个数据实现的增删改查操作。例如,Hash类型的HGET、HSET 和 HDEL,Set 类型的 SADD、SREM、SRANDMEMBER 等。这些操作的复杂度由集合采用的数据结构决定,例如,HGET、HSET和HDEL是对哈希表做操作,所以它们的复杂度都是 O(1); Set 类型用哈希表作为底层数据结构时,它的 SADD、SREM、SRANDMEMBER 复杂度也是O(1)。
第二,范围操作,是指集合类型中的遍历操作,可以返回集合中的所有数据,比如Hash类型的HGETALL和Set类型的SMEMBERS,或者返回一个范围内的部分数据,比如List类型的LRANGE和ZSet类型的ZRANGE。这类操作的复杂度一般是 O(N),比较耗时,我们应该尽量避免。
第三,统计操作,是指集合类型对集合中所有元素个数的记录,例如LLEN和SCARD。这类操作复杂度只有O(1),这是因为当集合类型采用压缩列表、双向链表、整数数组这些数据结构时,这些结构中专门记录了元素的个数统计,因此可以高效地完成相关操作。
第四,例外情况,是指某些数据结构的特殊记录,例如压缩列表和双向链表都会记录表头和表尾的偏移量这样一来,对于List类型的LPOP、RPOP、LPUSH、RPUSH这四个操作来说,它们是在**列表的头尾增删元素,这就可以通过偏移量直接定位,所以它们的复杂度也只有O(1)**,可以实现快速操作。
高性能IO
我们通常说,Redis是单线程,主要是指 Redis 的网络 I/O 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。
为什么 Redis 要使用“单线程”?
多线程的开销不仅仅是线程本身的 TCB 的代价,更多的是多线程在访问共享资源的时候,为了保证资源的正确性,就需要有额外的机制保证,这个额外的机制,就会带来额外的开销。这就是多线程编程模式面临的共享资源的并发访问控制问题。
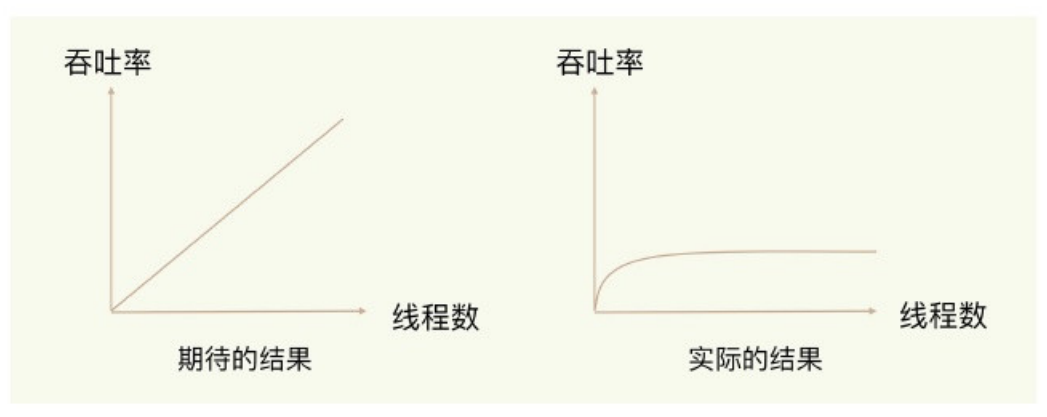
并发访问控制一直是多线程开发中的一个难点问题,如果没有精细的设计,比如说,只是简单地采用一个粗粒度互斥锁,就会出现不理想的结果:即使增加了线程,大部分线程也在等待获取访问共享资源的互斥锁,并行变串行,系统吞吐率并没有随着线程的增加而增加。
为什么 Redis 的单线程 I/O 这么快?
一方面,高效的数据结构设计,使得 Redis 在数据处理上能有更好的表现。另一方面,Redis 采用了多路复用机制,使其在网络中 I/O 操作能够并发处理大量的客户请求,实现高吞吐量。
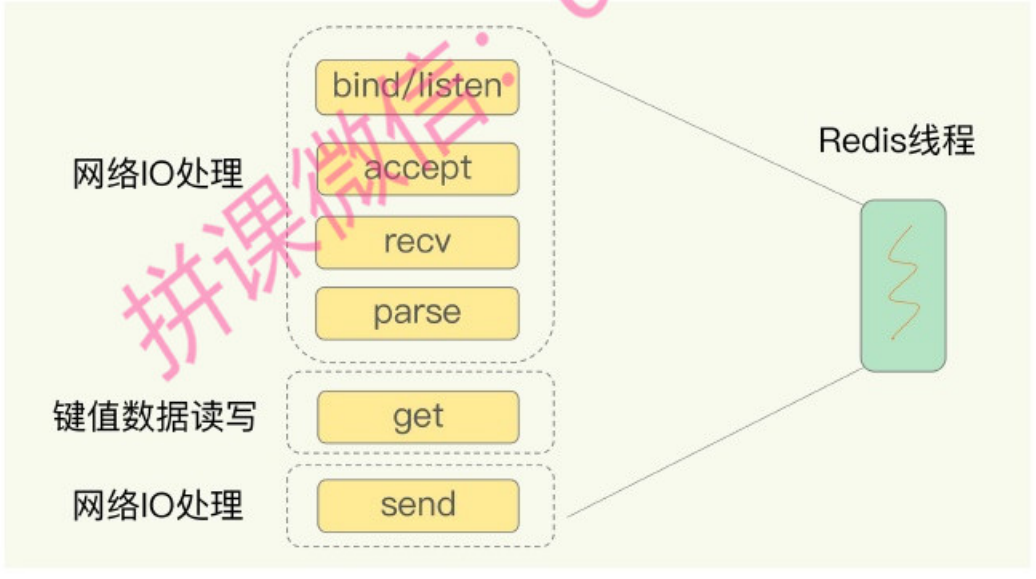
但是,在这里的网络IO操作中,有潜在的阻塞点,分别是accept()和recv()。当Redis监听到一个客户端有连接请求,但一直未能成功建立起连接时,会阻塞在accept()函数这里,导致其他客户端无法和Redis建立连接。类似的,当Redis通过recv()从一个客户端读取数据时,如果数据一直没有到达,Redis也会一直阻塞在recv()。
这就导致Redis整个线程阻塞,无法处理其他客户端请求,效率很低。不过,幸运的是,socket网络模型本身支持非阻塞模式。
非阻塞模式
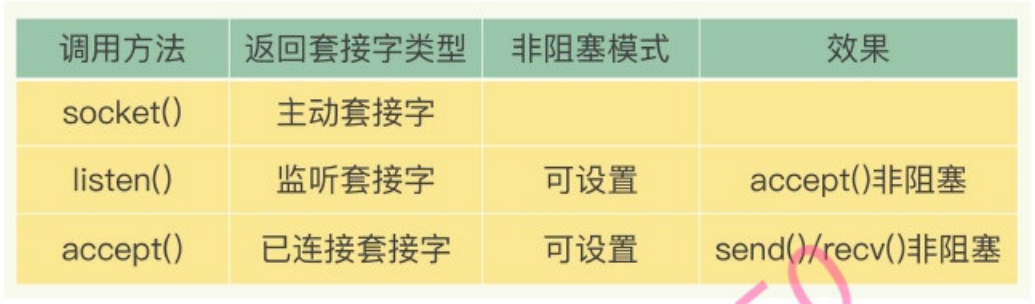
针对监听套接字,我们可以设置非阻塞模式:当Redis调用accept()但一直未有连接请求到达时,Redis线程可以返回处理其他操作,而不用一直等待。但是,你要注意的是,调用accept()时,已经存在监听套接字了。
虽然Redis线程可以不用继续等待,但是总得有机制继续在监听套接字上等待后续连接请求,并在有请求时通知Redis。
基于多路复用的高性能 I/O 模型
Linux中的IO多路复用机制是指一个线程处理多个I0流,就是我们经常听到的select/epoll机制。简单来说,在Redis只运行单线程的情况下,该机制允许内核中,同时存在多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求或数据请求。一旦有请求到达,就会交给Redis线程处理,这就实现了一个Redis线程处理多个IO流的效果。

为了在请求到达时能通知到Redis线程, select/epoll提供了基于事件的回调机制,即针对不同事件的发生,调用相应的处理函数。
这些事件会被放进一个事件队列,Redis单线程对该事件队列不断进行处理。这样一来,Redis无需一直轮询是否有请求实际发生,这就可以避免造成CPU资源浪费。同时,Redis在对事件队列中的事件进行处理时,会调用相应的处理函数,这就实现了基于事件的回调。因为Redis一直在对事件队列进行处理,所以能及时响应客户端请求,提升Redis的响应性能。
感觉这块的处理,比较像 JavaScript 的 acync/await 机制,有一个事件环,也是事件驱动的。
参考资料
- [极客时间] Redis 核心技术与实战
- [Redis 文档] Redis Document