Java虚拟机-垃圾回收机制
本站字数:108k 本文字数:2k 预计阅读时长:7min 访问次数:次Java语言优势之一就是程序员不用手动回收垃圾,减少了因为程序员自己,导致内存泄露的问题。Java的垃圾回收机制本篇文章将会从两个方面来描述这个问题:判定对象存活、垃圾回收算法。
对象已死?
判定对象是不是已经死亡,这是确定垃圾回收器是否需要对垃圾进行回收的标准。那么如何判定对象是否已经死亡,已经成为垃圾就成了一个问题,本节将会从三个方面来讨论这个问题。
引用计数法
对于一个对象,最直接的想法就是给每个对象加一个计数器,通过计数器来是想对对象的计数,如果对象的被引用次数达到了0,那么这个对象也就死亡了可以回收。引用计数法需要考虑很多的特殊情况来保证算法正常工作,例如,循环引用的问题。
A对象引用了B对象,而B对象又引用了A对象。这种情况下,如果不破解这种循环,就会导致他们的计数器一直不归零,垃圾收集器无法回收,导致内存泄漏的问题发生。但是,Java并没有使用这种方法来实现判定对象死亡,所以大可不必担心会因为这种原因造成的内存泄露。
可达性分析算法
目前主流的垃圾收集器都是通过可达性分析算法来保证对象是可达的。垃圾收集器维护一个 GC Root Set ,然后,利用对象之间的引用关系向下搜索,无法被搜索到的对象就是死亡的。这样的机制就可以保证对于循环引用的对象没有被引用,但是仍然可以被回收。

对于这个算法来说,Root Set的选取就显得格外重要了,Root Set 里面的对象一般包括:
- 虚拟机栈中引用的对象
- 静态属性引用的对象,Java类中静态变量的引用
- 常量引用的对象,例如 String Table 里面的引用
- 本地方法栈引用的对象
- 虚拟机内部的引用对象,例如Class对象
- 同步锁持有的对象
- 反映虚拟机内部状态的对象
当然在分代收集或者局部回收的过程中,对于只回收年轻代或者某块内存区域的垃圾收集器来说,Root Set的对象也不仅仅只有这块内存区域中的。其他内存区域中的对象,完全有可能引用回收部分的对象,如果不收集其他区域中的对象加入GC Root Set就会导致回收掉还在存活状态的对象。
finalization机制 拯救对象
虽然说对象死亡,对象就会被回收,但是这也不见得就没机会复活了。对象还是有一次被拯救的机会的,这个有机会被拯救的机制就是 finalization 机制。一个对象在死亡的时候,系统会回调对象的 finalize() 在这个回调中,对对象进行复活。可以参考下面的代码。
1 | package xyz.klenkiven; |
运行结果:
1 | 爷又活了没想到吧! |
通过上面的结果可以发现,对象是被救了一次,但是第二次却没有被救活,按理来说对象在死亡的时候,就会回调 finalize() 的,但是第二次却没有。这是因为第二次他已经被虚拟机从“即将被回收”的集合中移除,所以不会被调用回调 finalize() 自然也就没办法在救自己一次了。
常见的垃圾回收算法
在判定对象死亡以后,垃圾回收器就会开始进行垃圾回收了。市面常见的商业垃圾收集器,都是遵循“分代收集理论”进行设计的垃圾收集器。那么,本节将会从分代收集理论开始,讲述各种垃圾收集算法。
分代收集理论
分代收集理论建立在两个假说上:
- 弱分代假说:绝大多数对象都是朝生夕死的
- 强分代假说:熬过越多次垃圾收集过程的对象就越不容易死亡
通过上面两个重要的假说,建立起了一个这样的图景,每次程序运行都会产生大量的对象。大量的对象其实都是朝生夕死的,可以专门将这样的对象存放到一个区域,这个区域就叫做新生代区域。而将那些不容易死亡的对象放到另外一个区域,叫做老年代。
但是这样武断的划分就可以了吗?如果老年代的对象引用了新生代的对象,或者老年代引用了新生代的对象,这个时候进行垃圾回收标记的时候,回收新生代就难免得扫描所有的老年代对象,而回收老年代的时候也得扫描所有的新生代对象。这就需要另外的经验法则:
- 跨代引用假说:跨代引用相对于同代引用占据少数
根据这条假说就不需要扫描整个老年代了,而是建立一个全局的数据结构,这个结构可以把老年代划分成若干块,表示出那一块内存会存在跨代引用。发生 Minor GC 的时候,只有包含了跨代引用的那块内存里面的对象才会被加入 GC Root Set 降低了扫描整块老年代的负担。
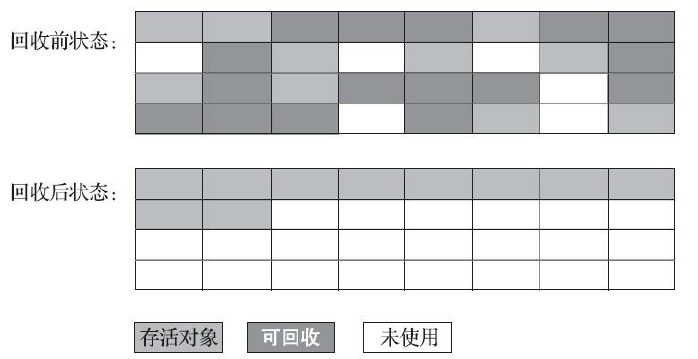
标记-清除(Mark-Sweep)算法
工作过程:
- 标记需要回收的对象,标记完成后统一回收掉所有标记的对象
- 标记所有存在的对象,然后回收所有未被标记的对象
缺点:
- 执行效率不稳定
- 内存区域碎片化
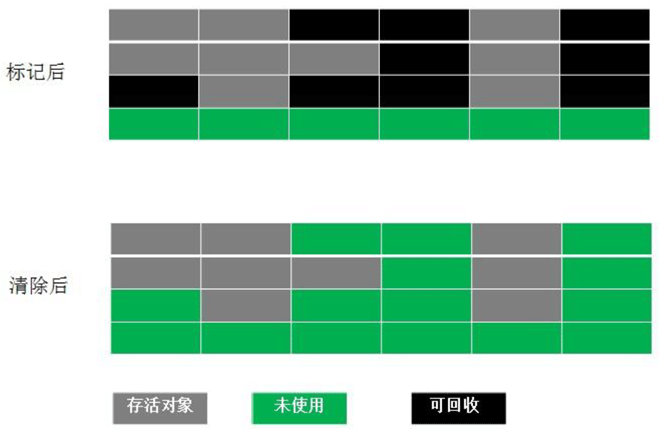
标记-复制(Mark-Copy)算法
工作过程(半区复制):
- 将内存分为两块,工作的时候只是用其中一块
- 发生垃圾回收的时候,将标记为存活的对象转移到另外一块区域
缺点:
- 需要两倍的内存空间
- 复制操作的时候,需要维护对象的指针
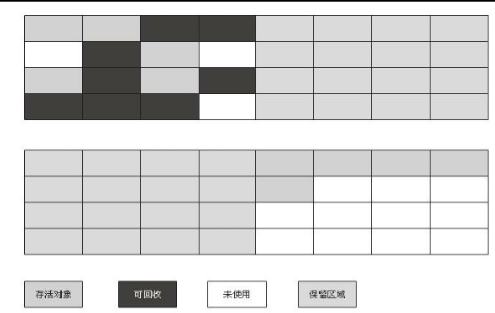
针对上面的缺点,在实现过程中演化出了更好的办法,将内存划分为三块:Eden,Survivor 1和Survivor 2。把新生代划分一块较大的空间(Eden)和两块比较小的区域(Survivor),每次分配内存只是用Eden和其中一块Survivor。发生垃圾回收的时候,将Eden和Survivor中任然存活的对象复制到另外一块Survivor空间上。这样的方式就可以保证仅仅浪费一块Survivor空间,而且这个空间大小并不是很大。
这种回收方式还有一个罕见的情况,也就是Survivor区域不够用了,这时候就需要一个“逃生门”的设计,发生这种情况的时候,依赖其他的内存区域例如老年代,进行内存分配担保。
标记-整理(Mark-Compact)算法
工作过程:
- 标记所有需要被回收的对象
- 将内存压缩到内存的一端,整齐排放
缺点:
- 效率上比复制算法低
- 和复制算法一样,需要调整对象的引用地址
- 移动过程中需要STW